


Apple veröffentlicht OpenELM-Sprachmodelle für die Arbeit ohne Internet
Apple hat eine neue Reihe von OpenELM-Sprachmodellen eingeführt, die lokal auf Geräten arbeiten, ohne dass eine Verbindung zu Cloud-Diensten erforderlich ist. Die Serie umfasst acht Modelle verschiedener Größen und Typen, die zwischen 270 Millionen und 3 Milliarden Parametern liegen.
Diese Modelle wurden auf riesigen öffentlichen Datensätzen trainiert, darunter 1,8 Billionen Token aus Quellen wie Reddit, Wikipedia und arXiv.org. Dank eines hohen Optimierungsgrades sind OpenELM-Modelle in der Lage, auf herkömmlichen Laptops und sogar einigen Smartphones zu laufen, wie auf Geräten wie Intel i9- und RTX 4090-PCs und MacBook Pro mit M2 Max-Chip demonstriert wurde.
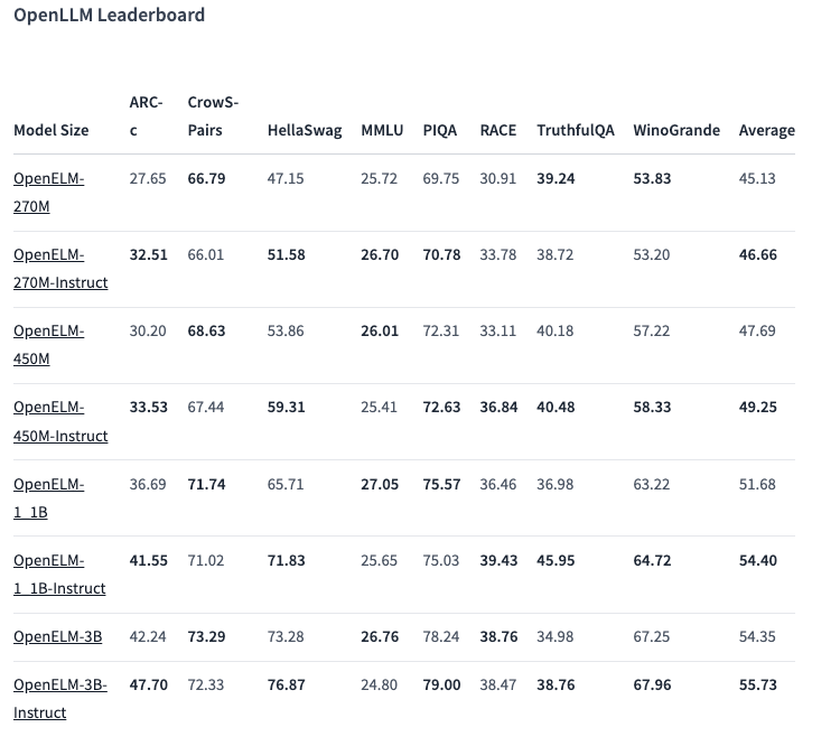
Eine der ausgewählten Optionen, ein Modell mit 450 Millionen Parametern, mit Anweisungen, zeigte hervorragende Ergebnisse. Das Modell OpenELM-1.1B mit 1,1 Milliarden Parametern erwies sich als 2,36% effizienter als das ähnliche GPT-Modell OLMo, wobei die Hälfte der Trainingsdaten verwendet wurde.
Im ARC-C Benchmark, der Wissen und logisches Denken testet, zeigte die vortrainierte Version von OpenELM-3B eine Genauigkeit von 42,24%. Bei anderen Tests, wie MMLU und HellaSwag, erzielte das Modell 26,76% bzw. 73,28%.
Apple hat außerdem den OpenELM-Quellcode auf der Hugging Face-Plattform unter einer offenen Lizenz veröffentlicht und bietet damit Zugang zu trainierten Modellen, Benchmarks und Anleitungen für die Arbeit mit diesen Modellen. Das Unternehmen warnt jedoch, dass die Modelle aufgrund fehlender Sicherheitsgarantien falsche, bösartige oder inakzeptable Antworten liefern können.